
Python Crawler

简单爬取网页
1 | from urllib.request import urlopen |
可以在pycharm上选择用本地浏览器打开,成功爬取网页!
Web 请求全过程
1.服务器渲染:
在服务器直接把数据和html整合在一起,同意返回给浏览器
可以在页面源代码中看到数据。
2.客户端渲染:
第一次请求只要一个html骨架,第二次请求拿到数据,进行数据展示。
页面源代码中没有数据。
HTTP 协议
http表示当前数据传输遵循http协议(超文本传输协议)
该协议下,一条信息三块内容:
请求:
1.请求行 -> 请求方式(get/post)请求url地址 协议
2.请求头 -> 服务器需要的附加信息
3.请求体 -> 一般是一些请求参数
响应:
1.状态行 -> 协议 状态码(如404 500 等)
2.响应头 -> 客户端需要的附加信息
3.响应体 -> 服务器返回的真正客户端需要使用的内容(html,json等)
请求头与响应头可能含有爬虫需要的信息
请求头:
1.__User-Agent__:请求载体的身份标识(请求来源)
2.Referer:防盗链(请求来源的页面,用于反爬)
3.cookie:本地字符串数据信息(用户登录信息,反爬token)
响应头:
1.cookie:本地字符串数据信息
2.其它字符串:一般是token字样,防止攻击与反爬
请求方式:
GET:显式提交(浏览查询)(直接显示在 url 中)
POST:隐式提交(更新数据)
Requests 模块介绍
安装:pip
搜狗搜索具有简单的反爬机制,可以通过伪装浏览器User-Agent的方式处理
1 | import requests |
requests 对 urllib 做了简化操作
也可以用输入的方式实现交互
1 | import requests |
案例:查找豆瓣电影分类排行榜 - 喜剧片
网址:https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
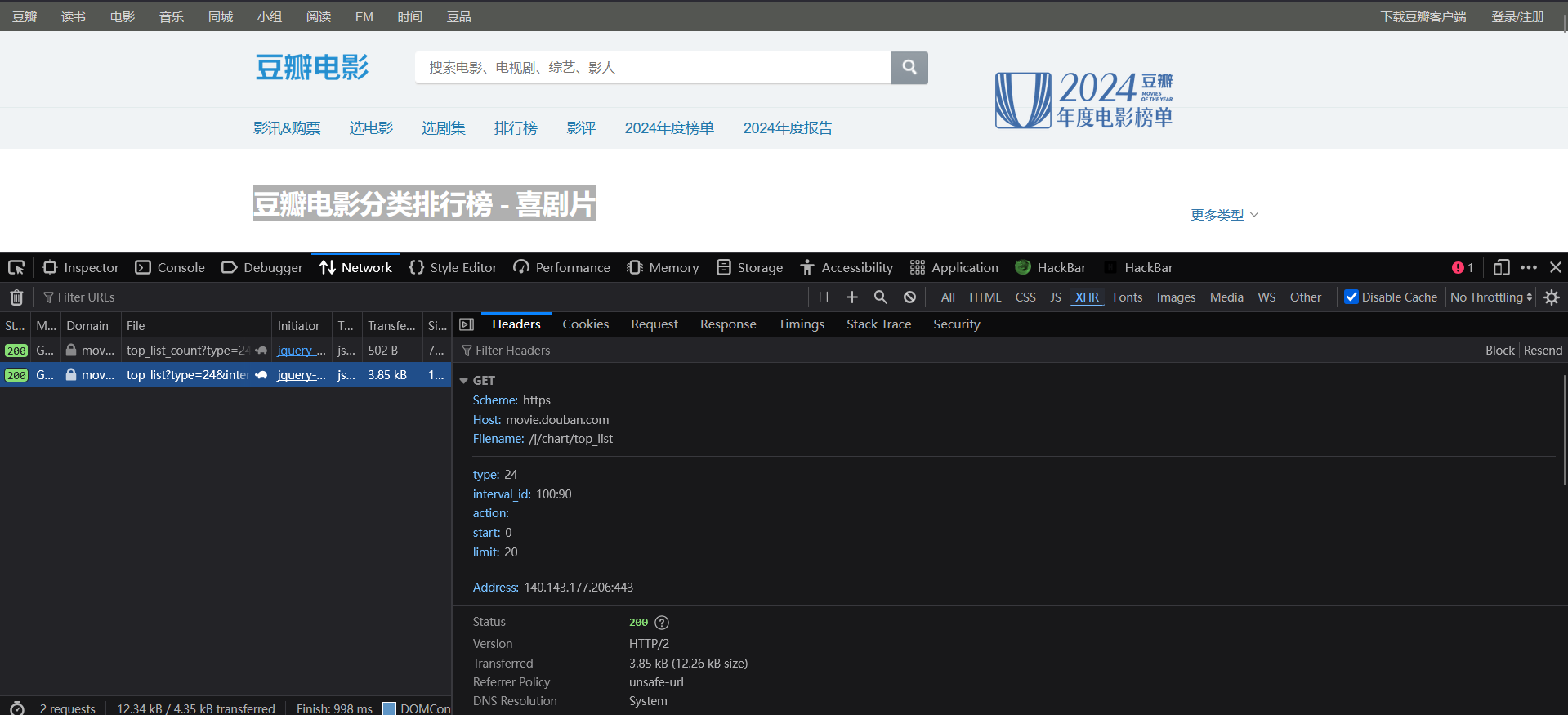
浏览器抓包工具:火狐浏览器 HackBar
F12 -> Network -> XHR (过滤次要响应)-> Headers
在左栏寻找需要爬取信息所在的响应
编写爬虫代码:
1 | import requests |
上下两份代码相同,建议使用下面的方式,更具有可读性,便于修改
1 | import requests |
运行后无响应:
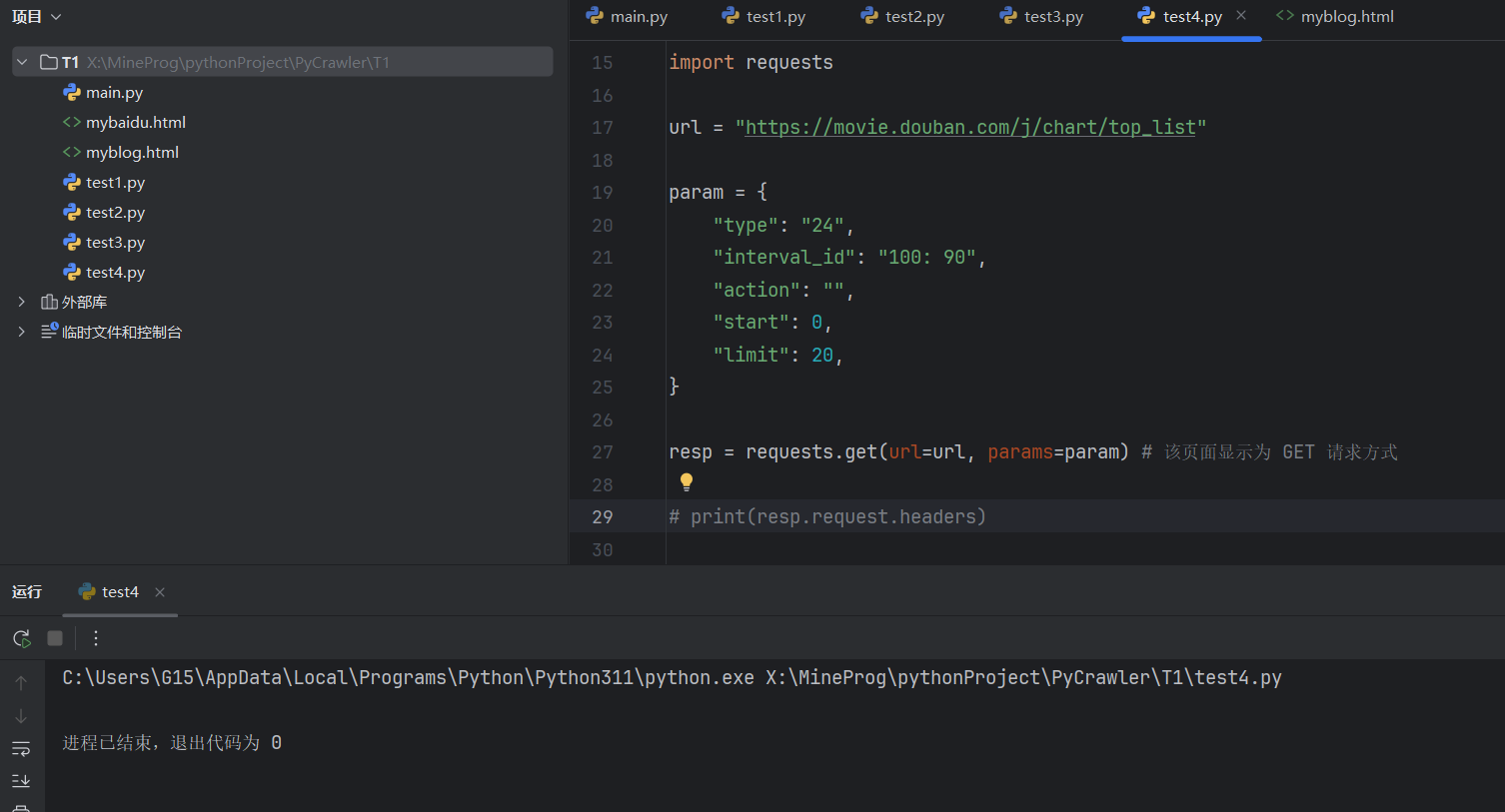
这是被网站反爬的结果
下面是想尽办法绕过反爬机制
尝试打印 headers 信息
1 | print(resp.request.headers) |
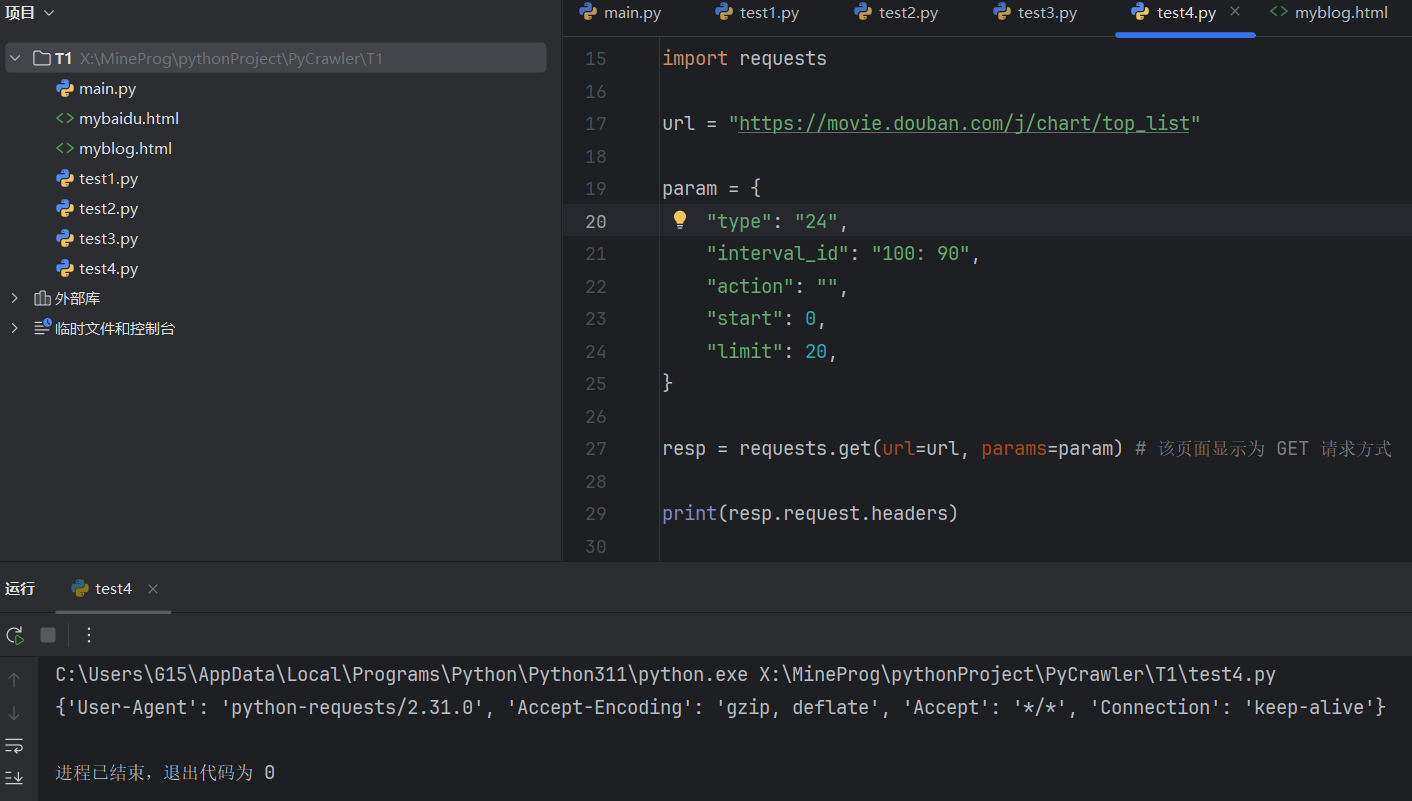
我们需要挨个检查结果参数。
首先尝试处理 User-Agent
从网页找到 ua 位置
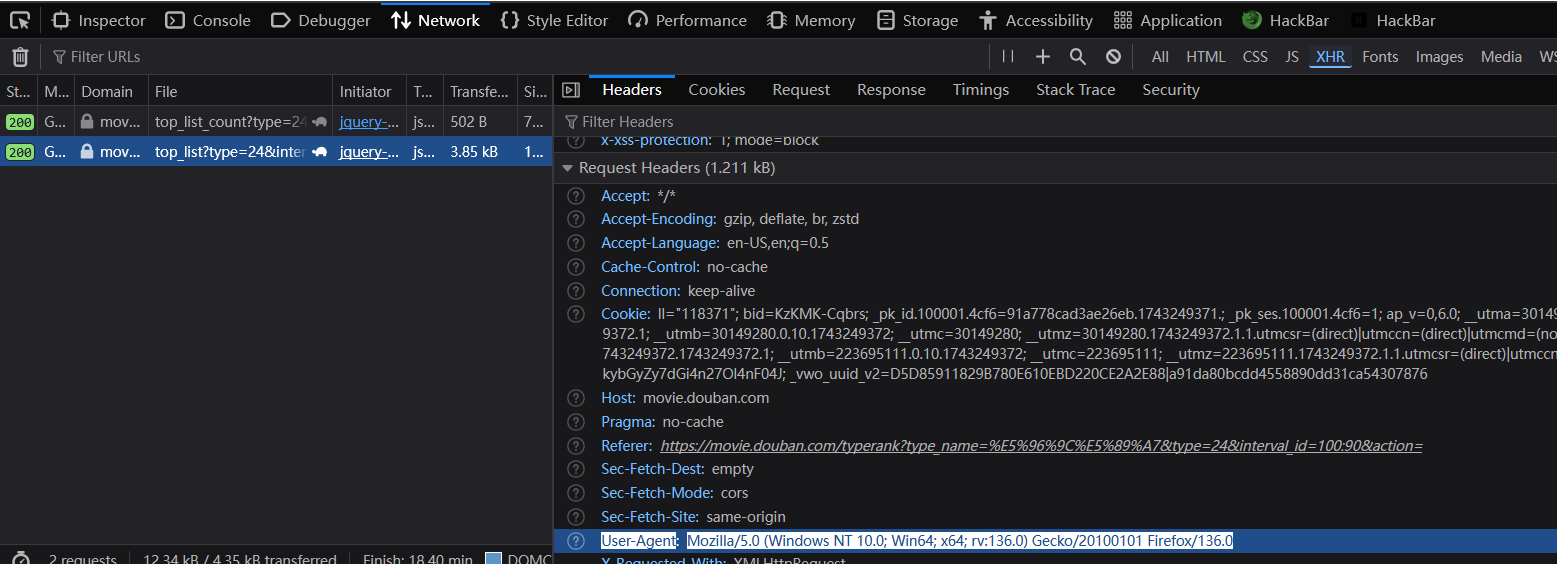
1 | import requests |
运行:成功读取并保存信息!!!
控制台打印只有一长行不便阅读,遂保存到文件中。
程序最后不要忘记加上
1 | resp.close() # 关掉resp |
2 数据解析
从整个网页冗杂的信息中提取我们需要的信息。
三种数据解析方式: re bs4 xpath
2.1 re解析
Regular Expression 正则表达式
- 标题: Python Crawler
- 作者: Cealivanus Kwan
- 创建于 : 2025-03-29 17:09:39
- 更新于 : 2025-04-30 09:45:04
- 链接: https://redefine.ohevan.com/2025/03/29/Python-Crawler/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。